2025-03-27

浏览量0
分享
2025年3月18日,卓驭AI首席陈晓智在NVIDIA GTC 2025发表主题演讲《基于端到端世界模型的生成式智驾体验》,分享了卓驭在端到端智能驾驶技术上的近期进展,并公布了卓驭基于端到端世界模型的全新一代智能驾驶功能——可支持自然语言交互的个性化生成式智驾方案GenDrive。
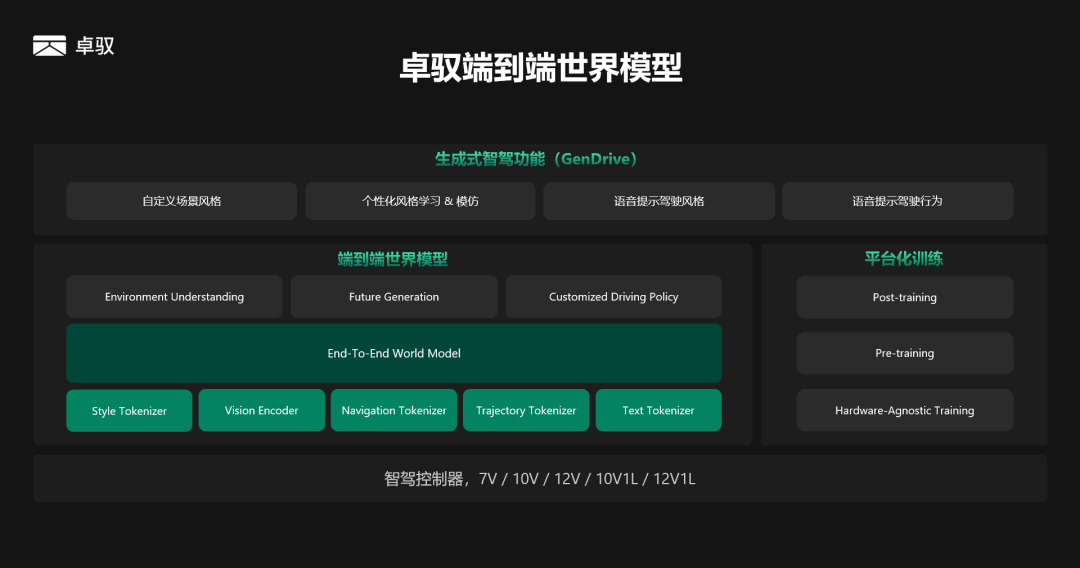
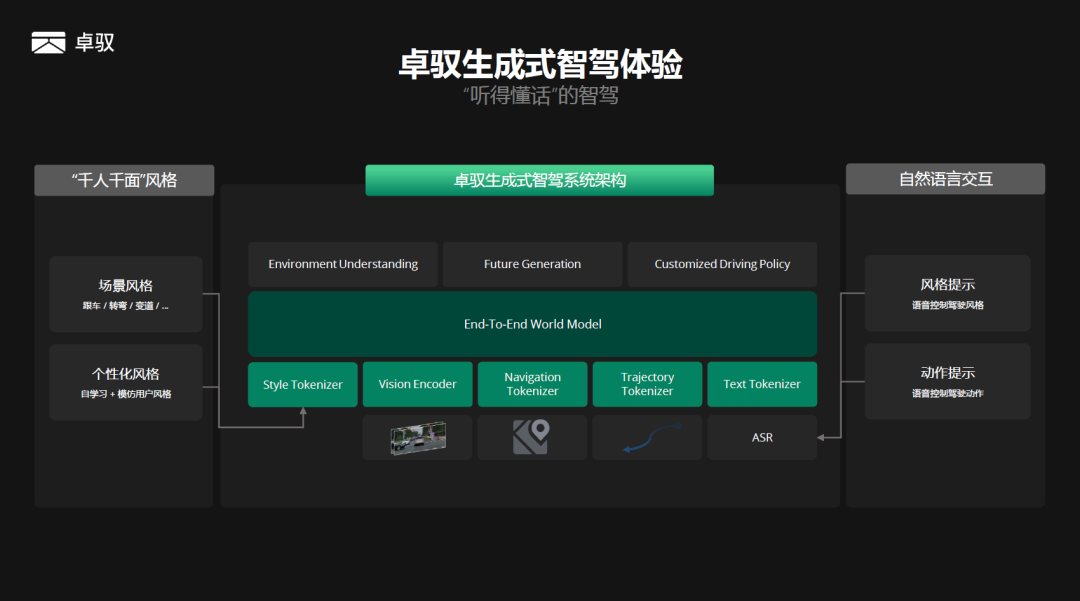
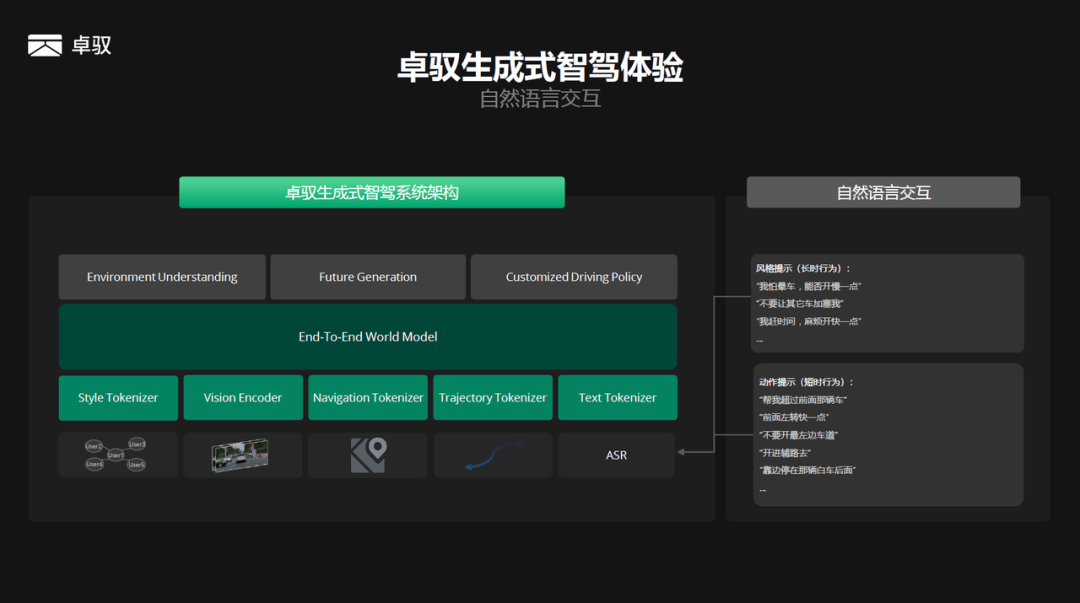
01 好的智驾体验标准 从拟人化到个性化 一个智能驾驶系统最终输出给车辆控制的是一条可执行的驾驶轨迹,这条轨迹通常以横纵向位置坐标和速度来表示,实际就包含了油门刹车和方向盘的信息。因此,一个智能驾驶系统的体验,实际就取决于这条驾驶轨迹。如果智能驾驶输出的轨迹不能反映用户的偏好,那么智驾体验自然也不符合用户预期。 端到端技术出现之前,用户对于智能驾驶系统的体验评价,往往用“安全”、“舒适”来评价;端到端技术出现后,无论是智驾行业还是终端用户,都开始关心第三个维度——“拟人化”。但单纯拟人化的智能驾驶体验,在卓驭看来仍然是不够的:因为现阶段端到端模型一般都是基于模仿学习来训练,从大量驾驶数据中学习,实际学到的是“平均人”的风格,并不一定是用户所喜欢的风格。 卓驭认为,好用的高阶智驾,除了足够拟人化,还需要满足用户个性化的驾驶需求。因此,卓驭在行业中首次提出了基于端到端世界模型的“生成式智驾”——GenDrive的概念,相对于传统的智驾体验,“生成式智驾”不仅可以给用户带来拟人化的体验,同时也能满足用户个性化的驾驶偏好。 02 卓驭端到端世界模型 让智能驾驶系统“听得懂话” 为实现个性化的驾驶,卓驭提出一种端到端世界模型的架构,它可以实现自定义的驾驶风格和驾驶行为,同时还能支持通过自然语言交互来实时改变、控制车辆的驾驶风格和动作:这是一个能理解用户,“听得懂话”的智驾系统,因此能更好的满足用户的个性化驾驶需求。 传统的端到端架构,更多是一种基于预测范式的端到端,即观测到一段传感器的输入,预测下一步的动作,因此它是一次性的动作预测的过程。陈晓智表示:“实际上用户的驾驶行为,由于环境的不同、周围动态交通参与者的交互、以及用户自身的驾驶偏好不同,它应该要具备多种可能性的输出。为了实现这点,我们采用生成式的技术来做端到端,通过世界模型来生成未来可能发生的N个平行宇宙,再结合用户偏好和各类环境信息来选择最优的轨迹输出。” 卓驭的端到端世界模型整体架构,在最底层为硬件平台,包括智驾控制器,可以适用英伟达的计算平台,比如DRIVE Orin/Thor SoC,并且可适配不同类型的传感器配置。在模型输入部分,卓驭通过Vision Encoder和若干Tokenizers来编码传感器数据、导航信息以及历史轨迹的输入。此外,在卓驭端到端世界模型架构中还会将驾驶风格以某种表达编码进模型,以及将用户的语音指令通过文本编码器输入到模型。对于模型的输出,则包括了周围环境的语义和几何的理解,以及对未来多种可能性的生成。最后输出的驾驶轨迹,则是与用户风格偏好、语音指令对齐后的结果。 对于端到端世界模型的训练,卓驭采用大模型典型的预训练+后训练的方式来进行,并且能够实现“硬件无关”的平台化训练,即针对不同传感器构型、不同芯片类型,只需训练一个模型,就能部署到不同的硬件构型。 03 生成式智驾GenDrive 让智能驾驶“人车合一” 基于上述端到端世界模型架构,卓驭的生成式智驾具备以下功能: 自定义场景级别的驾驶风格:比如跟车过程的风格(起步快慢、车距保持的距离等)、速度控制的风格、路口转弯的风格、变道的风格等。 在线学习和模仿用户的驾驶风格:基于用户一段时间的驾驶记录,模型自动学习出用户的驾驶风格偏好,整个学习过程只需用到车端算力,无需任何和云端的交互。同时GenDrive也能支持多个用户风格的学习,可以结合座舱内的人脸识别,自动绑定不同的用户ID,自动激活选择相应的用户风格。 可通过自然语言交互来控制驾驶风格和动作:驾驶风格是指长时的驾驶行为的刻画,比如用户通过语音对话“我容易晕车,能否开慢点”、“不要让其他车加塞我” 等,模型可自动识别出用户偏好的柔和或激进的驾驶风格。而驾驶动作指一个具体的、瞬时的行为,比如用户通过语音对话“不要开最左边车道”、“进入辅路”、“靠边停在那辆白车后面”等,模型即可理解用户意图,并实时改变模型的行为轨迹。 以上功能的实现,让卓驭的生成式智驾不仅可以实现真正千人千面的驾驶风格,满足不同用户的风格偏好,还能让智驾系统听得懂用户的诉求,实时对齐用户的驾驶意图。卓驭在行业中首次提出的生成式智驾体验能力,将会在今年内有相关车型进行量产搭载落地。